Reticular’s Research Sample: A Case Study on Interpretability in Protein Models
Authors: Nithin Parsan and John Yang
tl;dr
- Demonstrating sparse probing techniques from Gurnee et al. on ESM-2, we reveal how catalytic function in serine proteases is encoded through coordinated computation across different layers.
- Using a binary classification task, we identified a highly specific neuron in layer 1, complemented by a cooperative two-neuron circuit in layer 5.
- Through causal interventions, we show these neurons work together systematically: the early-layer neuron provides precise detection while the later circuit integrates this information with broader context.
- Learn more at reticular.ai and explore our visual findings at demo.reticular.ai.
Mechanistic interpretability has emerged as a powerful tool for understanding large language models, scaling even to frontier models like GPT-4 and Claude. But can these techniques help us understand biological language models? At Reticular, we believe controllable protein design requires precisely this kind of deep model understanding.
In this post, we demonstrate a proof-of-concept applying sparse probing techniques from Gurnee et al. to ESM-2, a protein language model. We show how just two neurons encode one of biology’s most fundamental features: the catalytic machinery of serine protease. By identifying and manipulating these neurons, we establish that the interpretability techniques developed for language models can transfer effectively to biological domains.
This work represents a small but concrete step toward Reticular’s mission: making protein design more controllable and interpretable. While language models can be steered through careful prompting, biological models require more precise control mechanisms. Understanding how these models encode biological features internally opens new possibilities for reliable protein engineering.
Why Study Serine Proteases?
In searching for biological features to probe in ESM-2, we needed a test case that would parallel the elegance of Gurnee et al.’s sparse probing demonstrations. Just as they showed how language models encode grammatical features like verb tense or compound words through specific neurons, we wanted to find similarly crisp, binary features in protein sequences.
Serine proteases offer an ideal parallel because they represent a clear binary property: either a sequence has a functional catalytic serine or it doesn’t. We know that mutating the catalytic serine abolishes function, giving us ground truth labels that are rare in biology. [1]
Creating a Clean Dataset
To translate these biochemical insights into a machine learning task, we constructed our dataset from the well-characterized trypsin family (EC 3.4.21.4) in SwissProt. Our positive examples are wild-type sequences with verified activity. For negative examples, we systematically mutated the catalytic serine to all 19 other amino acids, creating sequences we know are non-functional.
This gives us a clear binary classification task: can we find neurons in ESM-2 that specifically encode the presence of a functional catalytic serine? More importantly, this setup lets us distinguish between neurons that merely detect serine residues and those that specifically encode catalytic serines — a distinction that will prove crucial in our analysis.
The simplicity of this binary property makes it an excellent test case for exploring whether the interpretability techniques from language models can transfer to protein domains. If we can identify neurons that selectively encode this well-defined catalytic feature, it would suggest these methods can help us understand how protein language models represent biological properties more broadly.
Methods & Technical Approach
We used ESM-2, a protein language model trained on 65M protein sequences. The specific variant we used (ESM2-t6–8M-UR50D) has 6 layers with a hidden dimension of 1280, meaning each layer contains 1280 neurons that we can probe for interpretable features.
Data Processing Pipeline
Our pipeline follows three main steps:
- Activation Extraction: For each sequence in our dataset, we extract the post-GELU activations from the feed-forward layers of ESM-2. This gives us a tensor of shape (batch_size, sequence_length, 1280) for each layer.
- Sequence Length Aggregation: Since proteins have variable lengths and we’re interested in a specific position (the catalytic serine), we aggregate the sequence length dimension by taking the maximum activation across positions. This reduces our tensor to (batch_size, 1280).
- Final Preprocessing: After aggregation, we split our data into training and test sets, maintaining a balanced distribution of positive (wild-type) and negative (mutated) examples. It’s worth noting that the choice of splitting methodology can significantly impact results. [2]
Sparse Probing Methodology
Following Gurnee et al., we implemented several methods for identifying important neurons: mean activation difference between classes, mutual information between activations and labels, L1-regularized logistic regression, one-way ANOVA F-statistic tests, Support Vector Machines (SVM) with hinge loss, and optimal sparse prediction using cutting planes.
Each method aims to identify the minimal set of neurons needed to classify our sequences, with different tradeoffs between speed, interpretability, and guarantees of optimality. For detailed comparisons of these methods and their practical implementations, we refer readers to the original paper.
We evaluate these methods using standard binary classification metrics (precision, recall, F1) with a focus on out-of-sample performance. Importantly, we follow the paper’s recommendation to use F1 score as our primary metric given the inherent class imbalance in our task — there are many more ways for a protein to be non-functional than functional.
Results: Finding Neurons that Encode Catalytic Function
Performance Across Probe Methods
Following Gurnee et al.’s methodology, we compared different sparse probing approaches on our serine protease task. Here are the out-of-sample F1 scores excluding layer 5 across methods for different sparsity levels (k):

When analyzing the overlap between different probing methods (logistic regression, mutual information, mean difference, and SVM), neuron 1269 in layer 1 was the only neuron consistently identified across all methods and sparsity levels k. [3]
Mechanistic Analysis Through Causal Intervention
To understand how neuron 1269 encodes catalytic functionality, we performed a series of causal interventions by manipulating its activation (see Gurnee et al. for details). We discovered an intriguing asymmetry in the neuron’s behavior:
The most striking finding came from comparing different types of interventions:
- Complete ablation reduced predictions by 18.0%
- Negative scaling (-2x activation) caused a dramatic 70.8% reduction
- Both effects were highly specific to catalytic serines (p = 0.029)
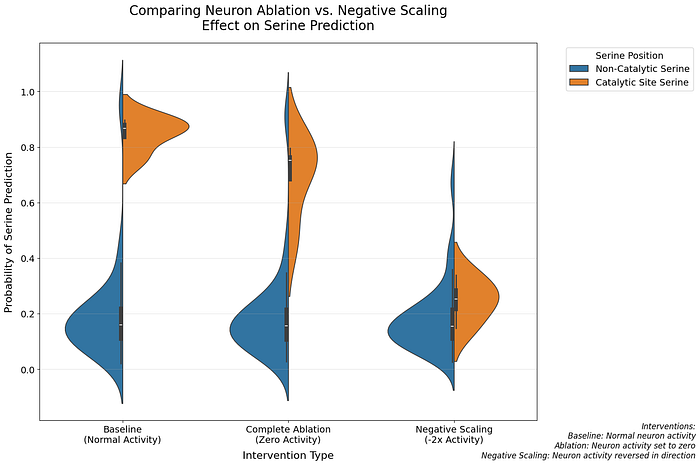
This asymmetric response suggests neuron 1269 plays a more sophisticated role than simple feature detection. The stronger effect of negative scaling compared to ablation indicates the neuron may be encoding directional information about catalytic functionality. [4]
A Complementary Circuit in Layer 5
Our analysis revealed a second mechanism for encoding catalytic functionality in layer 5. When examining F1 scores specifically for this layer, we identified a two-neuron circuit (neurons 106 and 110) achieving strong performance (F1 = 1.000) with k=2.
In summary (see Appendix A for detailed results):
- Both neurons consistently identified by multiple methods
- Strong individual effects (activation difference of 1.560 for neuron 106)
- Complementary activation patterns
- Clear specificity for catalytic vs non-catalytic serines
Cross-Layer Interactions
To better understand how these mechanisms work together, we examined the interaction between neuron 1269 and the layer 5 circuit. By simultaneously manipulating neurons across layers, we discovered evidence of sophisticated cross-layer computation:
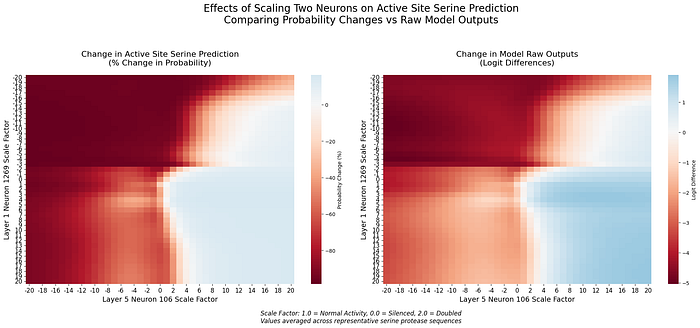
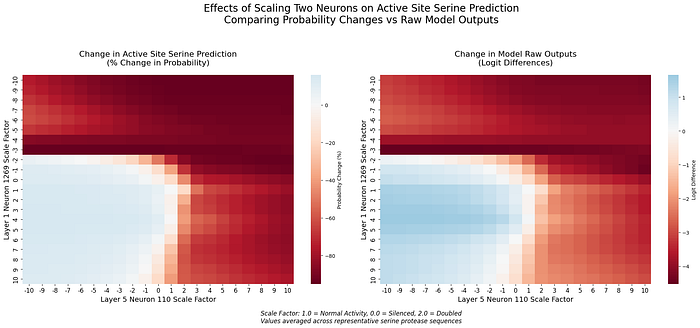
Several key patterns emerge (see additional detials in [5]):
- Asymmetric Influence: The early-layer neuron 1269 shows stronger modulation of layer 5 effects than vice versa
- Transition Boundaries: Sharp changes in prediction occur when both neurons shift from positive to negative scaling
These findings suggest ESM-2 employs different encoding strategies at different processing depths. While neuron 1269 serves as an early, precise feature detector, the layer 5 circuit appears to integrate this information within a broader sequence context.
Broader Implications: Sparse Feature Encoding in Protein Models
Our key finding — that catalytic activity is encoded through a precise early-layer detector working with a late-layer circuit — hints at something fascinating about how protein language models work. While these models learn from mountains of sequence data without any explicit knowledge of biochemistry, they appear to organize and encode meaningful biological features across different processing depths, strikingly similar to text-based language models [6]. The discovery of coordinated cross-layer computation for detecting catalytic sites provides strong evidence for our mission. At Reticular, we’re working to make protein design more controllable and interpretable. Finding such clear, compact representations of important biological features is a promising first step. But there’s still much work to be done.
Looking Ahead: Challenges and Open Questions
Our work with catalytic serines gives us a foothold in understanding protein language models, but we’re cognizant of the limitations and open questions posed.
Limitations
- Our analysis focused on ESM-2’s smallest variant (8M parameters)
- We identified layer-specific mechanisms in a simple binary property
- Our validation relied on well-established biochemical ground truth
- Our probing methods might miss more distributed representations
Most biological properties aren’t as cleanly organized across layers as catalytic serines. How do models encode messier features like:
- Binding affinity (a continuous spectrum)
- Thermal stability (emerges from global structure)
- Conformational changes (dynamic properties)
We’ve barely scratched the surface of how model scale affects these representations and how different architectures compare.
Get Involved
We’re actively seeking collaborations to expand this work:
- Working with / designing proteins? We’d love to deploy our technology to enable you to achieve your milestones faster. Schedule a chat at nithin [at] reticular.ai
- Mech Interp Researcher? If you’re interested in biological applications of interpretability, we have compute resources and interesting problems.
Reach out to nithin [at] reticular.ai — we’re excited to explore how mechanistic interpretability can make biological models more reliable and controllable.
[1] This property is close to the semantic examples in the sparse probing case studies: like compound words, the meaning depends on local context; like programming language detection, it requires broader structural understanding; and like grammatical features, it offers unambiguous ground truth.
[2] This is particularly true for biological data where sequence similarity between train and test sets can lead to inflated performance metrics. We took care to ensure our test set contained truly held-out sequences with low similarity to the training data.
[3] To examine consistency in neuron identification, we conducted an overlap analysis across four methods: logistic regression, mutual information, mean difference, and SVM. Neuron 1269 was consistently identified 100% of the time across all methods and k values, suggesting a fundamental role. In contrast, other neurons (e.g., 207, 818) were identified inconsistently, with no other neuron showing more than 50% consistency across methods.
[4] Statistical validation highlights the significance of neuron 1269. For catalytic sites, it showed a strong effect size (Cohen’s d = 8.523 for negative scaling) and a significant distribution shift (KS statistic = 1.000, p = 0.029). In contrast, for non-catalytic sites, the effect was minimal (Cohen’s d = 0.099) with no significant changes observed (KS statistic = 0.062, p > 0.99).
[5] Analysis of cross-layer interactions reveals distinct patterns when neuron 1269 interacts with neurons 110 and 106. With neuron 110, strong suppression effects are observed when both neurons are negatively scaled, creating a clear decision boundary around neutral activation and highlighting nonlinear effects, especially in probability space. In contrast, interaction with neuron 106 shows more gradual transitions, with complementary activation patterns that suggest cooperative computation. Different patterns emerge between logit and probability spaces for each interaction.
These interactions align with the original characterization of layer 5 neurons, where neurons 106 and 110 have opposing effects on serine prediction: neuron 106 is positively correlated, while neuron 110 is negatively correlated. Neuron 1269’s interactions reflect this complementarity, creating sharp transitions with neuron 110 (which opposes serine prediction) and smooth modulation with neuron 106 (which enhances it). The preservation of these opposing roles in cross-layer interactions suggests that this complementarity is fundamental to the model’s processing of catalytic sites.
[6] A note on architectural comparisons: While Gurnee et al. found interpretable features primarily in middle layers of Pythia models (which have 6–32 layers), our findings in ESM-2 reveal a different pattern: a precise feature detector in layer 1 complemented by an integrative circuit near the output in layer 5 of its 6-layer architecture. This difference is notable — while we’re using similar probing methodology, the layer-wise organization appears distinct from traditional language models. Finding interpretable features at both extremes of the network, rather than concentrated in middle layers, may reflect fundamental differences in how protein language models organize information, or could be related to ESM-2’s smaller scale and different architecture. The presence of sophisticated cross-layer interactions further suggests protein models may employ unique computational strategies compared to their text counterparts.
Appendix A: Detailed Analysis of Probing Neurons in Layer 5
Here are the out-of-sample F1 scores on a held-out test set across methods for different sparsity levels (k) including layer 5:
Several striking findings emerge:
- Most methods achieve perfect F1 scores (1.000) with just k=2 neurons
- Random selection performs poorly across all k values, validating our methodology
- SVM shows the strongest single-neuron performance (0.667)
- The performance plateaus completely after k=2, suggesting we’ve found a minimal representation
Our analysis converged on two key neurons in Layer 5 that appear to encode catalytic serine functionality. Notably, some methods identified alternative neurons (e.g., Neuron 287 in logistic regression showed an inverse relationship), but the 106–110 pair emerged as the most reliable across methods. Here are their detailed statistics:
Neuron 106 emerges as the primary feature detector:
- Consistently identified across all methods
- Large mean activation difference (1.560)
- Strong effect size (2.462)
- Clear separation between positive (8.153) and negative (6.593) cases
Neuron 110 appears to play a supporting role:
- Identified by multiple methods (MI, Mean Diff, SVM)
- Moderate but consistent effect size (1.158)
- Smaller but significant activation difference between classes
Detailed Analysis of Neuron Behavior
By incrementally scaling neuron activations from -10x to +10x their baseline values, we observe highly controlled effects on the model’s serine predictions.
Neuron 106
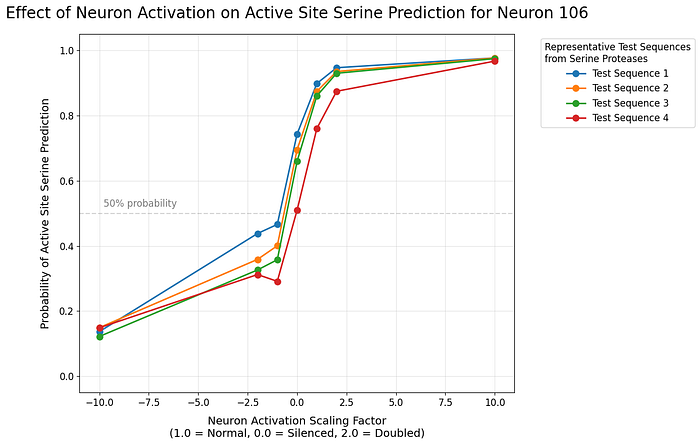
Neuron 110

Neuron 106 shows a strong positive correlation — increasing its activation consistently boosts the model’s prediction of catalytic serines. The relationship is remarkably linear in logit space, suggesting this neuron directly encodes catalytic serine functionality.
In contrast, Neuron 110 exhibits more complex behavior. While it generally opposes Neuron 106’s effects, its impact is more pronounced when down-regulated than up-regulated, suggesting a regulatory role.
Interaction Analysis
When scaled together, we observe both synergistic enhancement and mutual cancellation:
- Synergistic Enhancement: When both neurons are scaled in compatible directions (106 up, 110 down), we see superadditive effects on serine prediction confidence
- Cancellation: When scaled in opposing directions, they can effectively neutralize each other’s impact
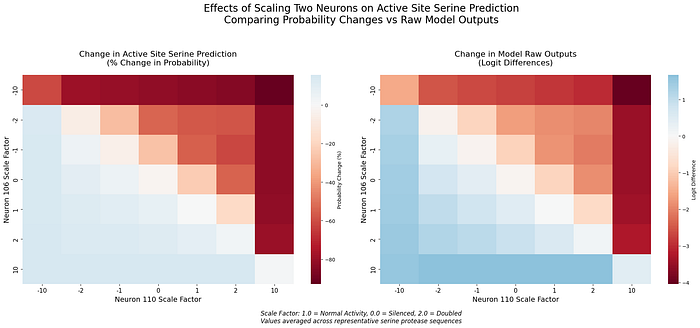
The heat-map visualization reveals clear patterns in how these neurons modulate each other.
Verification via Neuron Ablation: Catalytic vs Non-Catalytic Serines
To verify that these neurons specifically encode catalytic serines rather than serines in general, we examined their impact across different serine populations.
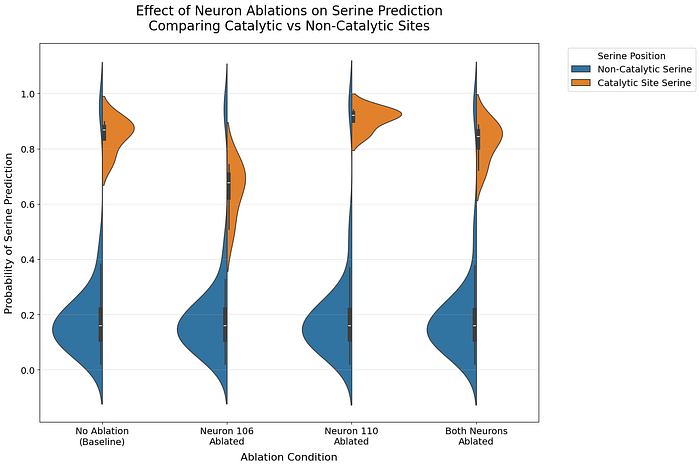
The violin plots reveal a striking specificity:
- Ablating these neurons dramatically affects predictions for catalytic serines
- Non-catalytic serine predictions remain largely unchanged
- The effect is most pronounced when both neurons are ablated together
We performed Kolmogorov-Smirnov tests to quantify these differences. Ablating neuron 106 showed a significant difference compared to no ablation (KS = 1.000, p = 0.029), whereas ablating neuron 110 (KS = 0.750, p = 0.229) and ablating both neurons (KS = 0.500, p = 0.771) did not show significant differences. For non-catalytic serines, all comparisons showed minimal effects (KS statistic < 0.031, p > 0.99), confirming that these neurons are specifically tuned to catalytic serines.
